Learn how Rutter can help you accelerate your product roadmap, save engineering headaches, and grow revenue
This post was put together by Zev Stravitz, Jay Patel and Marko Fejzo
Today, we’re excited to launch the new Rutter documentation. As a developer-focused company, we want to make it as easy as possible for developers to use Rutter and that starts with our documentation.
In the last few months, we shipped a lot of features that would touch multiple endpoints, thus requiring our Engineers to update multiple documentation pages. The manual process of updating docs led to inconsistency and gaps creating a poor user experience.
With the new Rutter documentation, our documentation is produced and updated from the source code itself, which is a best practice from developer focused companies like Stripe, Github, Shopify, etc.
What’s New?
1. Accurate Documentation
a. Documentation from the Source Code - Having our documentation created from the source code helps keep our documentation up to date at all times without us having to manually update each endpoint when new features get shipped.
b. Multiple Checks for Correctness - Whenever our engineers make a change, using our build pipeline, we spin up a replica of our documentation site with their change applied to our API reference. This allows both the authoring engineer and the code reviewer to verify that the code and the documentation changes are in sync and remain accurate with each change.
c. Type-Safe Examples - All object examples including in our documentation are also validated for type-safety using a compiler during the build pipeline, which ensures that our schema definitions and examples are always in sync.
2. Better User Experience
We made a lot of changes to the user experience which now allows developers to find what they’re looking for faster and have an easier time reading our documentation. For example, previously, our schema page had nested tables and it was hard to read it in one glance. Today, it’s a lot easier to read.
3. OpenAPI Spec
We now have an OpenAPI spec as a source of truth which allows engineers to easily build idiomatic SDKs for our API using SDK generators (list available on https://openapi.tools/#auto-generators).
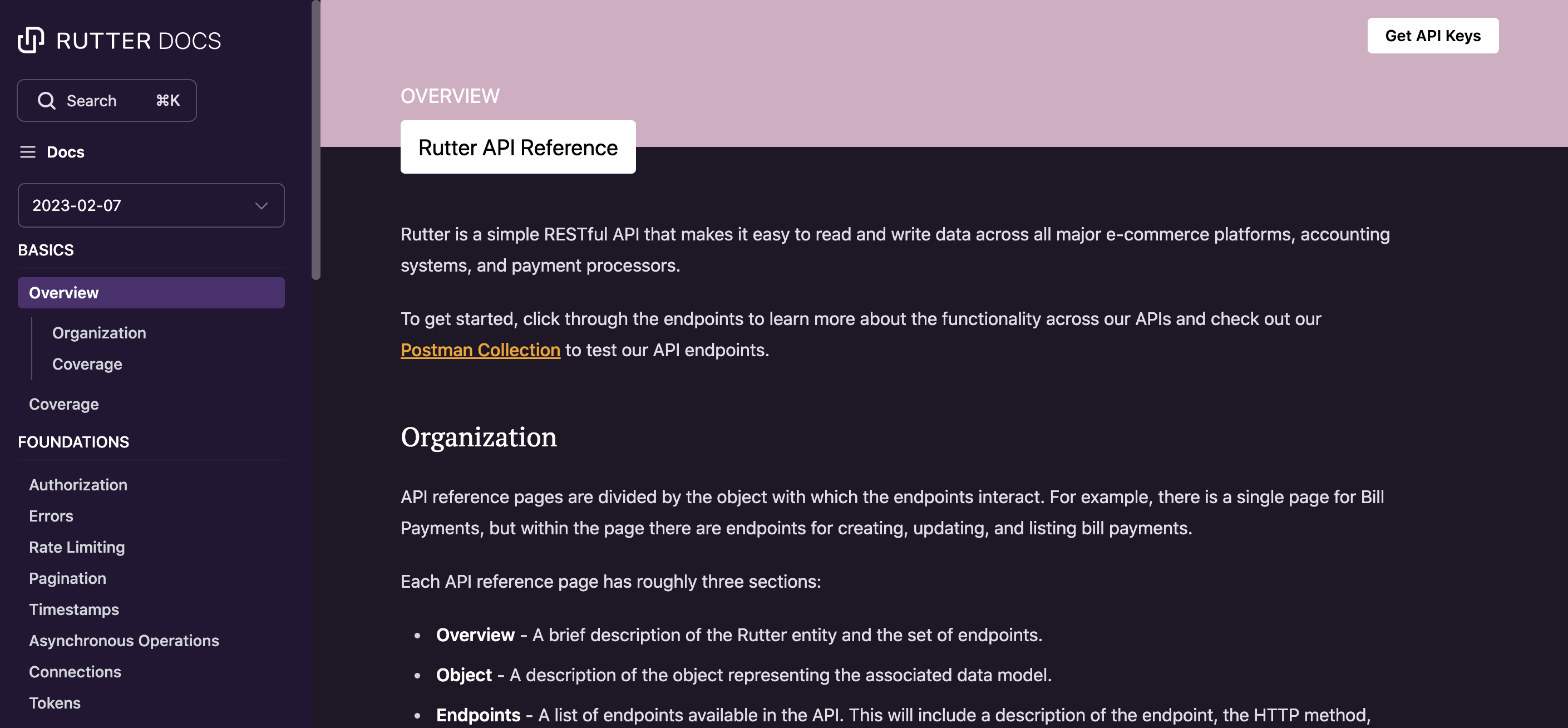
Our documentation before this update
It doesn’t matter if you build a great product if no one knows how to use it.
Previously we used a vendor to manage and host our documentation, and while this helped us have a functioning a documentation site with minimal Engineering effort, we found it limiting as we scaled as a company. For one, our documentation frequently went out of date as we updated code. Even though we kept things backwards compatible for our generally available (GA) endpoints, we’d often iterate on a data model as we piloted a new workflow with a customer, and it was during this period that keeping track of changes was hard as we rapidly shipped new functionality.
Stale docs break trust. At Rutter we’ve integrated with platforms who don’t value the API contract, and it’s broken our integrations. We have mature systems internally for handling platform failures which allow us to diagnose the root cause immediately, but our customers shouldn’t have to go through this trouble - our docs should simply reflect the contract we define in code.
Docs from source
We auto generate our docs by producing and leveraging an OpenAPI spec first. The OpenAPI spec is generated using router metadata we maintain in our code base. The documentation site is built by reading the OpenAPI spec and generating HTML.

The Router we use is a custom router that takes in metadata such as Zod schemas for request/response types, and which platforms (NetSuite, Amazon, Quickbooks, Shopify, etc.) we support for that endpoint. Here an example of what a route handler looks like:
.png)
And the schema definition for a vendor object looks like:
.png)
To create Zod schemas that could hold all the metadata necessary for an OpenAPI spec, we had to extend the Zod package. So we monkey patched methods like example() and title() which are used to define examples and titles in the spec. This allowed us to do interesting things like type-check the object examples in our docs too, so we can be sure JSON snippets are always up to date.
Each time the router is updated, we trigger generation of an updated OpenAPI spec. If we detect a change to the OpenAPI spec, we will trigger a new deployment of our documentation. During the deployment of the documentation, we generate path parameters which are used at build time to statically generate all of our API reference pages. This way, we don’t have to generate pages when a user requests them.
For pages that use server-side rendering we wanted to make sure the page was still performant. It was imperative we avoided making API calls to fetch spec information because our OpenAPI spec files are thousands of lines, so moving this over the network is costly. So we took advantage of the Next.js 13 App Directory and react server components (RSC’s) to read the collocated spec from our filesystem.
To generate these pages we wrote a library of OpenAPI parsers that read the spec to gather data for UI components. These utilities are battle tested to ensure we handle edge cases like recursive component references.
For our authoring experience, we wanted something that reflected the ethos of docs as data instead of docs as code, so we chose Stripe’s Markdoc framework. Markdoc makes our reference pages readable and easy to edit for folks who aren’t experienced with frontend tooling.
Quick Thanks
We owe the Neon Database team for open-sourcing their website which provides a production-level example of the Next.js app directory in use.
Thanks to Darius Cepulis from Mux for his great post on Mux’s documentation which served as technical inspiration.
Thanks to Sagar Poudel for his work building the initial custom router.
If you're interested in learning more about Rutter and our Universal API for Commerce and Accounting, reach out here.